计算机中的时间
 times read
times read
Contents
时间在计算机中是个十分重要的概念,几乎所有程序都会与时间打交道。而计算机不能找人问时间,也没法自己看表,它是如何管理时间的?
单机中的时间
产生来源
CPU 有固定的时钟周期,而 Linux 可设置 CPU 的时钟中断,即每隔固定的 CPU 时钟周期,就会产生一次时钟中断。产生中断时,会执行中断表中对应的 Linux 内核程序,内核程序会更新系统时钟。每次时钟中断被成为一次 tick 。
在 Linux 中,产生 tick 的频率可设置,可设定为 100、250、300、1000 HZ。tick 的频率越高,则执行时钟中断程序就越频繁,系统内核维护的时间精度就越高,但耗费在维护时间的资源就越多。
时间的类型
墙上时间
wall clock time,也被称为钟表时间,表示真实世界中走过的时间。
比如压缩一个文件,从开始压缩到结束压缩,真实世界时钟经过的时间。
时钟回拨
由于各种原因(时钟同步、用户调整系统时钟),需要向前回拨调整本机时间(把当前时间调整为之前的某时间),则会出现时间倒退的情况。比如,当前时间为 2022-01-01 10:00:02 ,需要把当前时间调整为 2022-01-01 10:00:00 ,则调整后就会出现时间倒退 1s 的情况。
若某程序依赖 wall clock time 运行,则可能导致程序出错。
对于一定时间范围内的时钟回拨,Linux 下可通过 adjtime 系统函数,通过让时间走的慢一些的方式,来微调时间,最终达到时钟回拨的效果。
比如之前计算机的 1s 就是墙上时间的 1s,使用 adjtime 来调整时间,可以使得墙上时间过了 1.1s,而计算机中只过了1s,从而使得计算机中的时间慢慢向前微调,不会出现时钟回拨的情况(这是个比较夸张的例子,事实上微调幅度比这小得多)。
进程时间
程序占用 CPU 的时间(不包含阻塞时间)。对于多核CPU,该时间为程序中各线程占用各个核的时间总和。该时间通常用于程序性能测试、数据统计等。
Linux 下的 time 命令行工具能获取 user-time、system-time、real-time 这三类时间,从而得知进程时间和墙上时间。
|
|
其中,进程时间等于 sys 和 user 这两个时间之和;墙上时间等于 real 时间。
单调时间
Linux 下使用开机到现在经历的 tick 次数,经换算作为单调时间,该时间单调递增。用户设置系统时间、NTP 服务调整时间都不能改变单调时间。
Linux 下可使用 uptime 命令查看系统已运行时间(单调时间)。
分布式中的时间
NTP 协议同步时间
分布式系统中,由于机器时钟的误差,会导致不同机器间时间偏差越来越大。因此校准机器上的时间是一项重要工作。
可以通过与其他机器通信来校准时间,但通信也会耗费时间。因此 NTP 协议通过计算并剔除通信时间,来减小误差。多次使用 NTP 协议并剔除异常值,可进一步减小误差。
NTP 协议流程如下:
服务端为授时服务器,客户端为需要同步时间的机器。客户端在本地时间 t1 发起请求,服务端在其本地时间 t2 接收到消息,t3 时刻发出消息(t2、t3均写入到消息体中),客户端在本地时间 t4 收到响应。
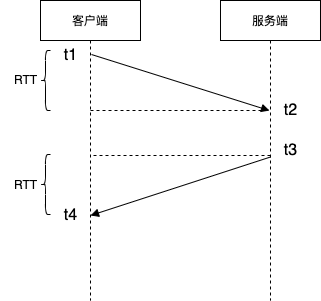
注意,t1、t2 是客户端的本地时间,而 t3、t4 是服务端的本地时间,比较不同机器上的时间是没有意义的,后面的计算会注意这一点。
可得出往返请求在网络上的耗时为 $ (t4 - t1) - (t3 - t2) $ 。假设请求的往返时间相同,则 $ RTT = \frac{(t4 - t1) - (t3 - t2)}{2} $
在 t4 时刻,客户端通过计算可得到,此刻的准确时间(以服务器端时间为准确时间)为 $$ t3 + RTT = \frac{t4 + t3 + t2 - t1}{2} $$
服务端与客户端时间差值为 $$ 服务端时间 - 客户端时间 = t3 + RTT - t4 = \frac{(t3 - t4) + (t2 - t1)}{2} $$
通常在公共互联网环境下,使用 NTP 协议能保持几十毫秒的误差。而在局域网内,误差可以达到1毫秒内。
逻辑时钟
由于在分布式系统中,同步时间会不可避免地受到网络影响而造成误差。因此,Lamport 提出了 逻辑时钟 的概念,其根据事件的因果关系而不是绝对时间来确定时间的先后顺序
偏序关系
首先定义一个偏序关系
把事件 a 发生在 b 之前定义为 a -> b 。则以下三种条件都满足 a -> b
- a和b是同一个进程内的事件,a发生在b之前,则
a -> b - a和b在不同的进程中,a是发送进程内的发送事件,b是同一消息接收进程内的接收事件,则
a -> b - 如果
a -> b并且b -> c,则a -> c
逻辑时钟
基于这个偏序关系,引入逻辑时钟算法:
分布式系统中每个进程 Pi 保存一个本地逻辑时钟值 Ci,Ci (a) 表示进程 Pi 发生事件 a 时的逻辑时钟值,C i的更新算法如下
- 进程 Pi 每发生一次事件,Ci 加1。
- 进程 Pi 给进程 Pj 发送消息,需要带上自己的本地逻辑时钟 Ci。
- 进程 Pj 接收消息,更新 Cj 为 max(Ci, Cj) + 1。
从以上定义可以很容易地得出下面推论
|
|
假定初始事件 a 的时间为 0,则其他事件对应的发生时间如图(A、B 为进程,a~e 为事件)
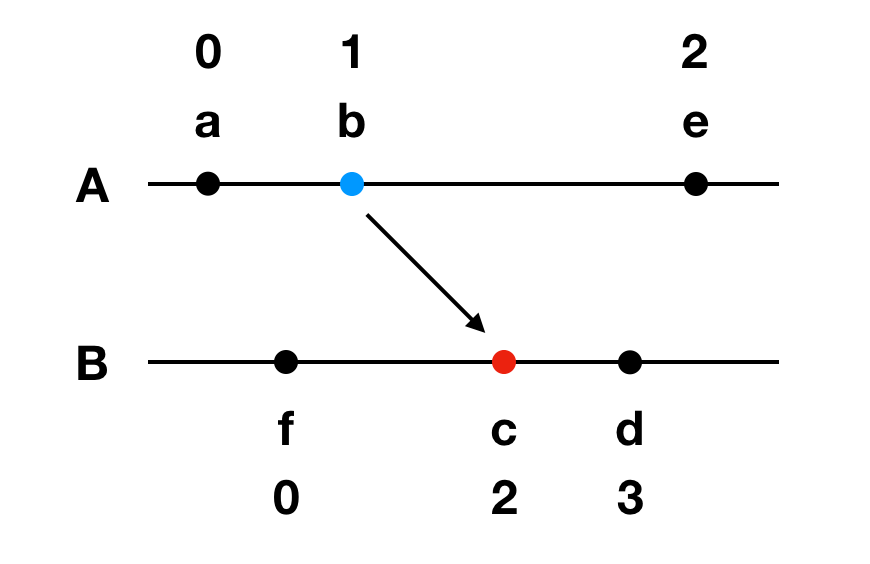
逻辑时钟是基于偏序关系的,因此只能确定分布式系统中部分事件的先后关系。
全序关系
通过指定进程的优先级,则可以将逻辑时钟拓展为全序关系。
Pi进程的事件a和Pj进程的事件b如果满足下面两个关系中的任何一个,则称 a => b,即事件a在全序关系上发生于事件b之前:
- Ci (a) < Cj (b)
- Ci (a) = Cj (b) 并且 i < j。
假设进程A的权重为1,进程B的权重为2,则得到的全序关系如下为 a => f => b => e => c => d
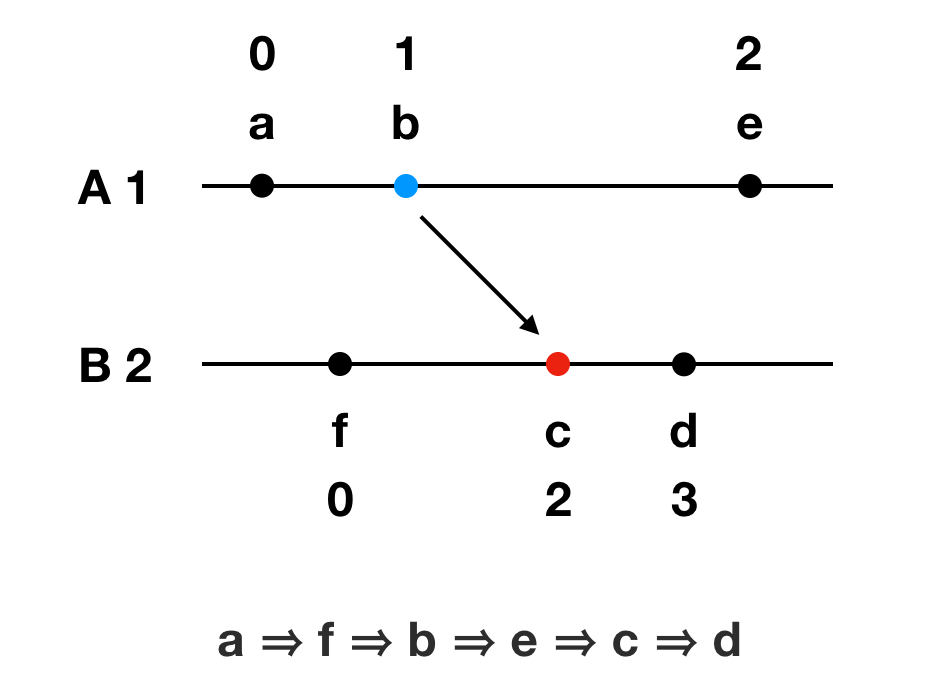
虽然可能存在这样的情况:物理时间上事件 e 发生于 d 之后,但是由于两个事件并没有因果关系,他们的排序结果是 e => d
向量时钟
逻辑时钟,能确定部分事件的先后顺序。而向量时钟是基于逻辑时钟发展而来,在每一个事件发生后,会向所有进程(节点)广播,各进程收到消息后更新本地的逻辑时钟。这样就确定了所有事件的时序关系。
TrueTime
TrueTime 是 Google 提出的分布式时钟同步方案。该方案努力提高物理时钟的精度,减少误差,并通过程序手动抹平误差的方式来保证分布式各机器时间先后顺序不错乱。
举个例子。某分布式事务要依次串行地在两台机器 A、B 上执行子任务,由于各机器时间不同,可能导致 A 机器上执行任务的时间晚于大于 B 机器。即机器 B 上的任务是在机器A之后执行,最后根据提交时间却发现 B 机器上的任务是先执行完的,这与实际情况不符。因此需要 TrueTime 来保证不同机器上的时间的顺序性。
首先介绍 TrueTime 的整体架构
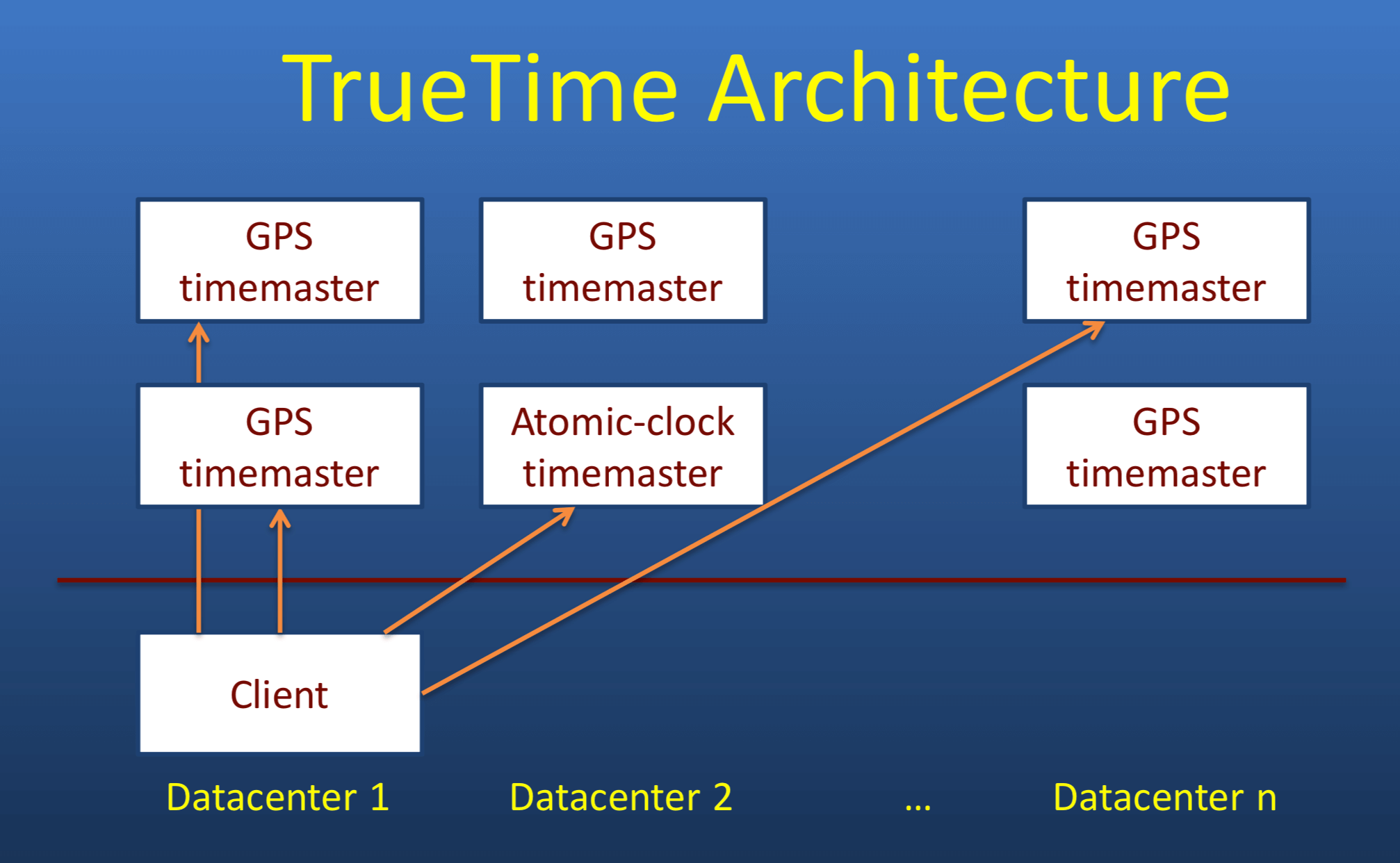
TrueTime 授时服务集群(图中上半部分),使用原子钟和GPS时钟作为时间源,不同集群间相互校验时间以减小误差。
Client 为业务集群中的机器,它定期从授时集群中拉取时间(当然也会进行数据校验,舍弃异常数据)。Client 侧能保证的时钟误差为 1~7ms。
软件层面,TrueTime 提供了三个API:
TT.now()返回的是当前时间的范围。由于时钟硬件误差的存在,这个当前时间存在一个不确定的范围,也即一个范围 [earliest, latest]。可以保证当前绝对时间一定在这个范围内,这个间隔范围最大是7msTT.after(t)判断传入的时间戳是否已经是过去的时间,也即 t < TT.now().earliest。TT.before(t)判断传入的时间戳是否是未来的时间,也即 TT.now().latest < t。
使用这三个API,就能保证分布式事务中,事务提交顺序与事务实际提交时间一致。
参考
https://github.com/freelancer-leon/notes/blob/master/kernel/time.md
https://blog.csdn.net/lqy971966/article/details/110234641
https://blog.csdn.net/Roland_Sun/article/details/106235963
Author Jakseer
LastMod 2022-12-20