Linux IO 模型-阻塞、非阻塞、同步、异步、多路复用
 times read
times read
Contents
[toc]
Linux 的设计哲学中有一条准则 万物皆文件 ,体现为:读取系统信息是读文件;获取用户输入是读文件;通过 socket 发送数据是写文件。不少操作是通过读写文件完成的。
而相对于 CPU 执行指令的速度,磁盘等介质读写数据的速度慢得多(见下表)。因此当前程序执行到 IO 指令后,并不能马上拿到 IO 读写结果。
| CPU | SDD 硬盘 | HDD 硬盘 | 网络 | |
|---|---|---|---|---|
| 时间单位 | ns | us | ms | ms |
注:1 ms = $10^3$ us = $10^6$ ns
如何处理 CPU 指令处理时间 与 各种介质读写时间之间的巨大鸿沟,是让 CPU 等一等还是让 CPU 先处理其它事情?就是本文接下来的内容。
IO 模型
同步阻塞 BIO
当前程序执行到 IO 指令时暂停,等待 IO 返回结果才继续向后执行。
用一个通俗点的场景来说:
去商场吃饭,想吃的餐厅还在排队,就坐在门外的椅子上专门等排位。
我想吃饭(开始读写文件),但是由于饭店做饭的速度(IO 读写速度)赶不上人们吃饭的速度(执行指令速度),于是我啥也不干,专心等排位(当前程序啥也不干,就等 IO 返回结果)
用一段 c 语言代码来演示效果:
|
|
程序执行后,就卡住了。此刻执行到 read 产生了 同步阻塞 情况,等待用户输入数据。只有用户输入完数据后,才会继续执行后续的 printf 等指令。
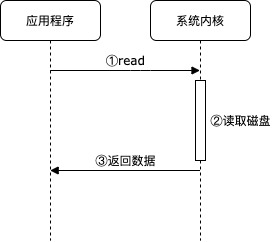
通过 strace 命令也可以看出,程序阻塞在 read 系统调用上
同步非阻塞 NIO
执行 IO 指令时,向系统提交读写请求,但并不等待 IO 执行结果,而是继续向后执行程序指令,后续再检查 IO 执行结果。
用一个通俗点的场景来说:
去商场吃饭,想吃的餐厅还在排队,于是就先叫号,然后去逛其它店,但会时常回来查看是否到号
我想吃饭(开始读写文件),但是由于饭店做饭的速度(IO 读写速度)赶不上人们吃饭的速度(执行指令速度)。于是我先排个号(提交 IO 申请),然后去逛其它店,过一会再回来看有没有排到我。
用伪代码来表示:
|
|
第一次调用 read 函数,会提交 IO 请求。后续程序会主动再次使用 read 查询读数据的进度,直到成功读取数据。 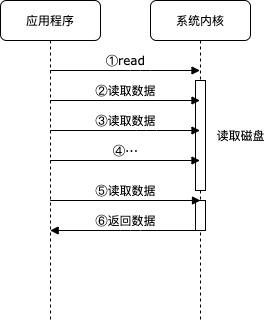
对比同步阻塞,同步非阻塞虽然不会导致程序卡住(阻塞),但是需要程序主动轮询去查询 IO 状态。
C语言实例代码:
|
|
异步非阻塞 AIO
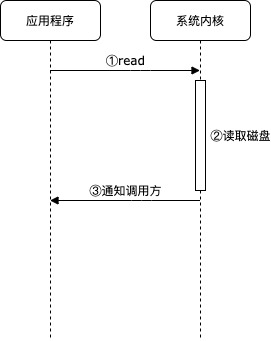
执行读写指令,提交 IO 请求时,并不等待执行结果,继续向后执行命令。当 IO 数据准备就绪时,系统会通知用户程序 IO 请求的执行结果。
用一个通俗点的场景来说:
去商场吃饭,想吃的餐厅还在排队,于是就先手机叫号,然后去逛其它店。当号排到时,手机会收到通知。
伪代码如下:
|
|
相比于同步阻塞、同步非阻塞模型,异步 IO 模型是系统主动通知用户程序,而不需要用户程序主动去获取 IO 结果。
IO 多路复用 IO multiplexing
同时发起多个阻塞的读写请求,当有一个请求完成,就结束阻塞态,让用户程序继续处理
假设有这样的场景:
某程序为网站的服务端,当用户请求时,读取用户数据并进行后续处理。而在同一时间内,可能会有多个用户请求。
如果还是使用 BIO,程序每次则只能读取并处理一个用户的请求。当并发量较高时,则可能会出现用户请求排队,等待服务端处理的情况。
这时就该使用 IO 多路复用了。使用 IO 多路复用,同时读取多个用户请求的数据,当有用户请求数据读取完毕时,就进行后续逻辑处理。避免了用户请求排队,等待服务器处理的情况。
还是用通俗的场景来举例子:
去商场吃饭,但是想每个餐厅都尝一下。因此每个餐厅都取号,哪个排到号了就吃哪个餐厅。
对于 BIO 模型,它是当前程序暂停,等待 IO 操作完成。而多路复用也是当前程序暂停,不过是等待多个 IO 操作的完成。因此相对而言,多路复用通常更省时些。
在 Linux 下,IO 多路复用有三种主要的系统调用,而本文主要说明这三种多路复用的大体原理与区别,具体用法及实现原理可看参考资料。
select
将要监听的 fd 以数组形式提交给系统内核,系统内核会轮询数组中 fd 对应的文件。若文件就绪或者超时时间到,则返回。
poll
将要监听的 fd 以链表形式提交给系统内核,系统内核会轮询链表中 fd 对应的文件。若文件就绪或者超时时间到,则返回。
epoll
将要监听的 fd 提交到系统内核,并将回调函数挂载到设备IO 上。当有设备 ready 时,回调函数修改对应 fd 的状态。当 fd 状态变更或超时时,epoll 返回到用户态。
| select | poll | epoll | |
|---|---|---|---|
| fd 最大数量 | 通常为 1024 | 无上限 | 无上限 |
| fd 拷贝情况 | 每次拷贝 | 每次拷贝 | 只拷贝一次 |
| 工作模式 | LT | LT | LT 与 ET |
| 时间复杂度 | O(n) | O(n) | O(1) |
参考文献
《UNIX 环境高级编程》
《Linux 系统编程》
Author Jakseer
LastMod 2021-09-25